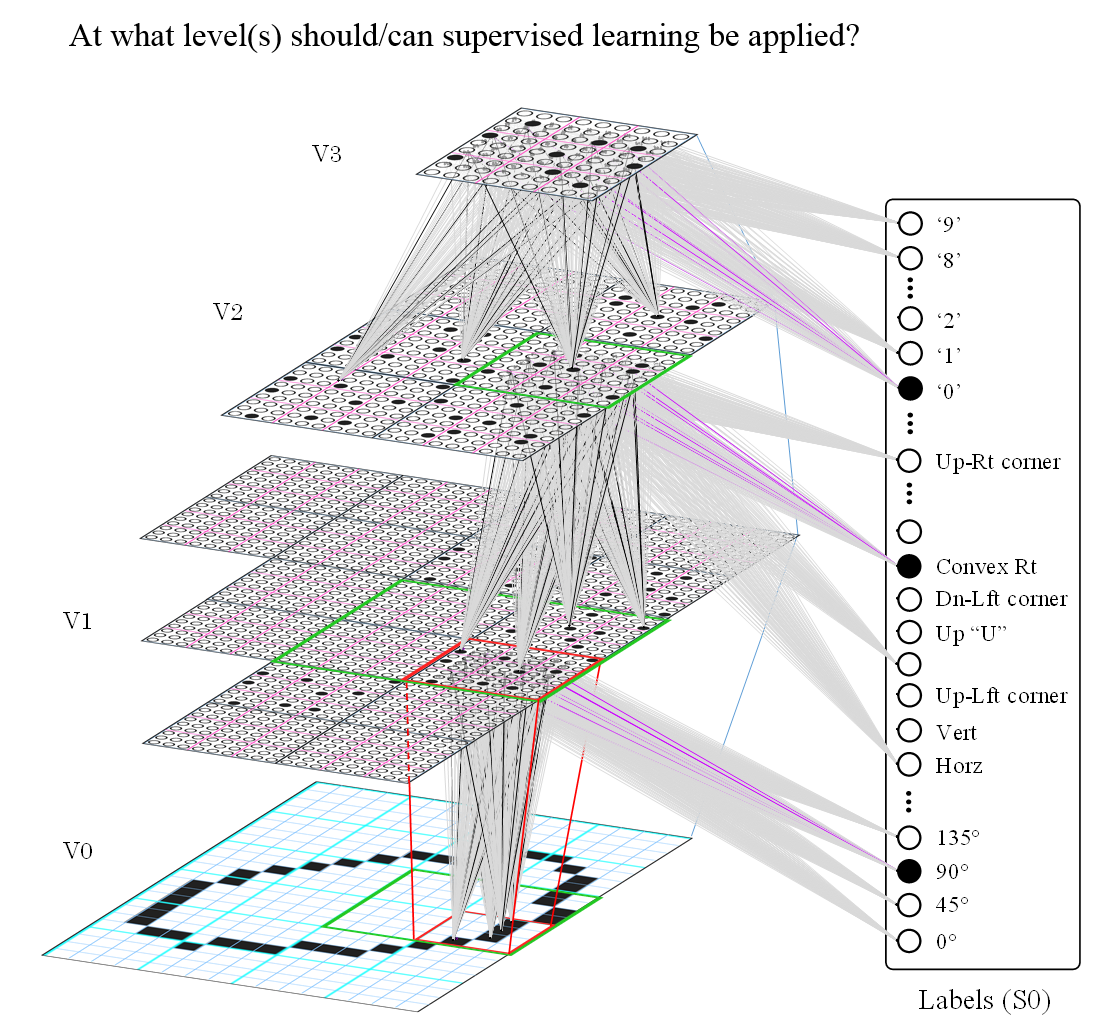
How multimodality is being implemented in Sparsey
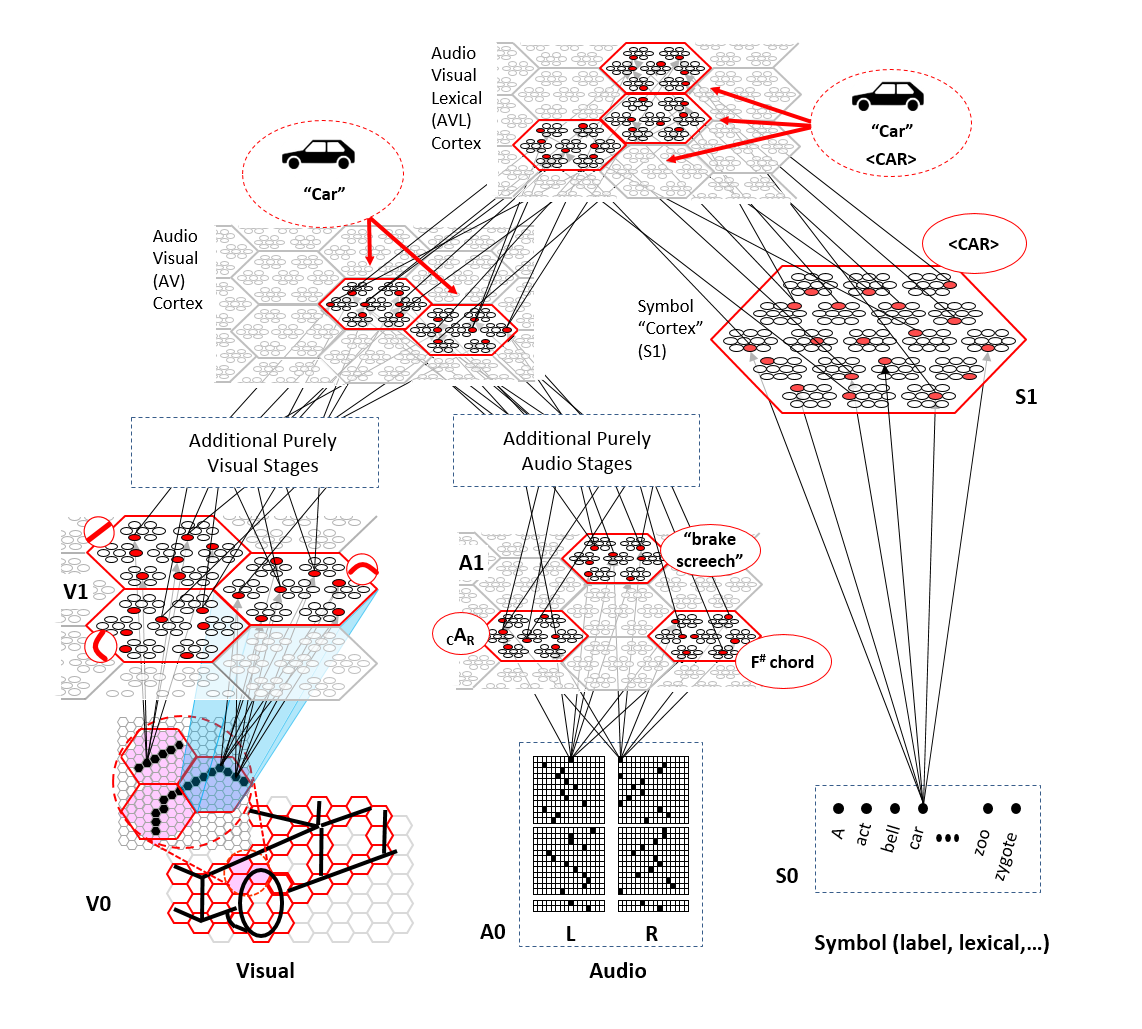
The figure shows a hierarchical Sparsey model with two sensory input modalities, visual and audio, eventually converging on higher-level multimodal regions, e.g., AV cortex. The SDCs assigned/learned in AV cortex represent multimodal inputs. We also have a third, symbolic, input field, to which we can present labels. The label inputs are converted to sparse codes in "symbol cortex" (S1) and those SDCs of symbols are associated, using the same unsupervised, essentially Hebbian learning, used everywhere else in the model. This essentially implements supervised learning via cross-modal unsupervised learning. In general supervised learning is required to learn arbitrarily nonlinear classes.
This is a highly simplified architectural scheme relative to what the brain implements/possesses. For one thing, the brain has no "symbolic cortex". Of course, we all learn symbols from scratch via unsupervised learning in and between sensory modalities like vision and audition, etc. And the visual and auditory processing can be broken out into many more stages and interactions.
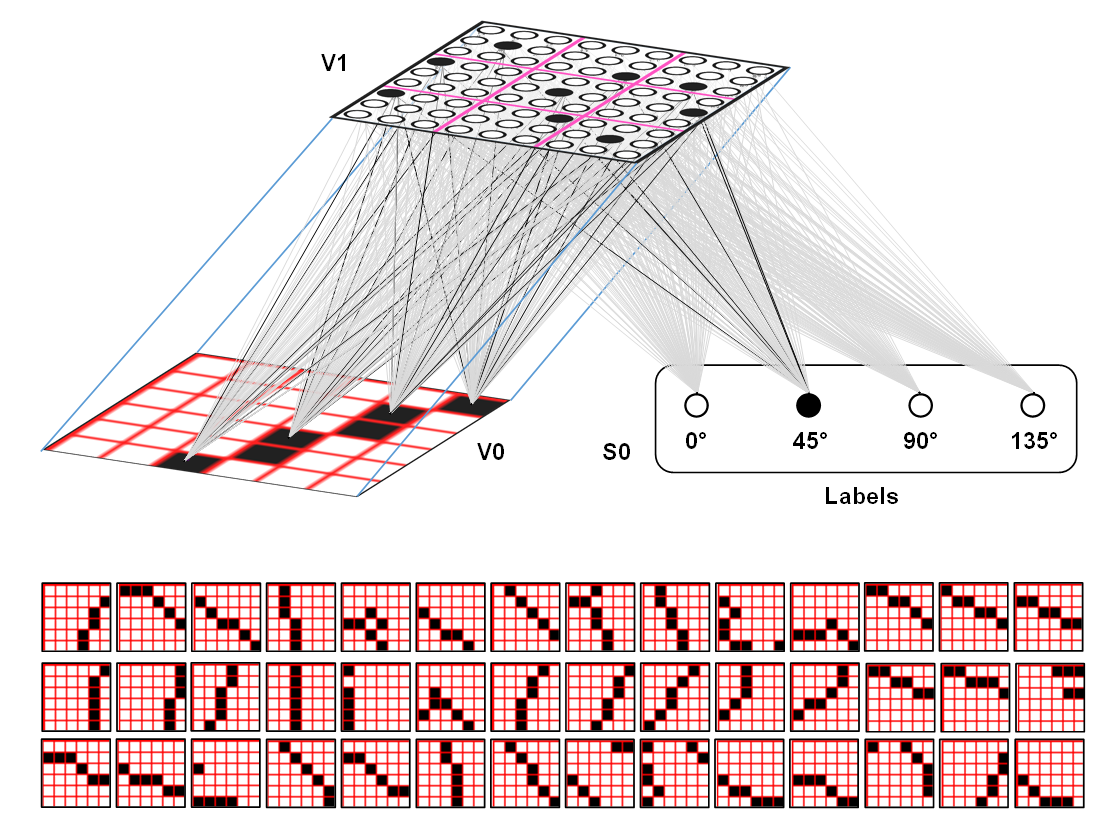
The figures below show the even simpler implementation of supervised learning that we are currently using. So far, we are still using only one input modality, vision. Though, we emphasize that the symbols (labels) themselves can be considered formally equivalent to just another input modality. We hope to begin true multimodal studies in the near future. As has long been argued, the problem of learning how to segment and label parts of the (spatiotemporal) world, will in fact be easier with more modalities present since discontinuities in one modality can act as (unsupervised) cues to aid segmentation in other modalities. This figure shows a single V1 mac whose input is a 6x6-pixel patch of visual space. The label field here has only 4 labels, i.e., we're assuming here that all possible inputs to a generic 6x6-pixel patch can be safely approximated by just four features. The rows at bottom show examples of actual inputs experienced by this V1 mac during its training phase. Whether or not such a coarse categorization (i.e., just 4 features) is justifiable here is open to debate; we feel there are strong reasons why something like this is quite reasonable.
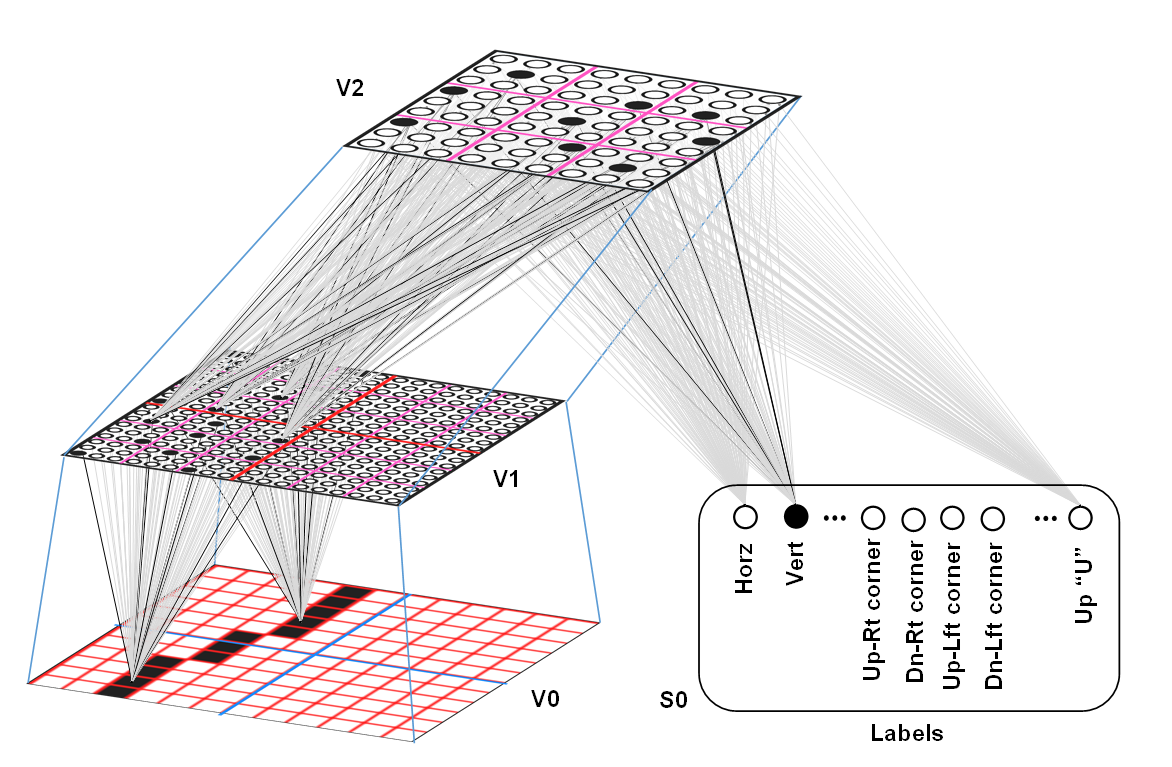
This next figure shows a 2-level implementation of cross-modal learning, where the top level (V2) mac receives input from four V1 macs, yielding a 12x12-pixel input space for the V2 mac. Of course, the space of possible inputs to the 12x12 patch is exponentially larger than for a 6x6-patch. However, if we limit the number of features representable by V1 macs to just 4 features [i.e., if we "freeze" the basis contained in each of these V1 macs, as apparently occurs in the real brain (cf. "critical periods")], then we drastically reduce the input space of the V2 mac. The label field in this case shows part of a reasonable set of V2 features. And, note that the label representations (S0) are now linked directly with V2 not V1.
This next figure shows a 3-level model, where the top-level (V3) mac's input space is 24x24 pixels. We've used such models to learn to recognize digits and letters. We will continue to do so, though these are purely spatial pattern recognition problems and we are currently concentrating on spatiotemporal (video) recognition problems.
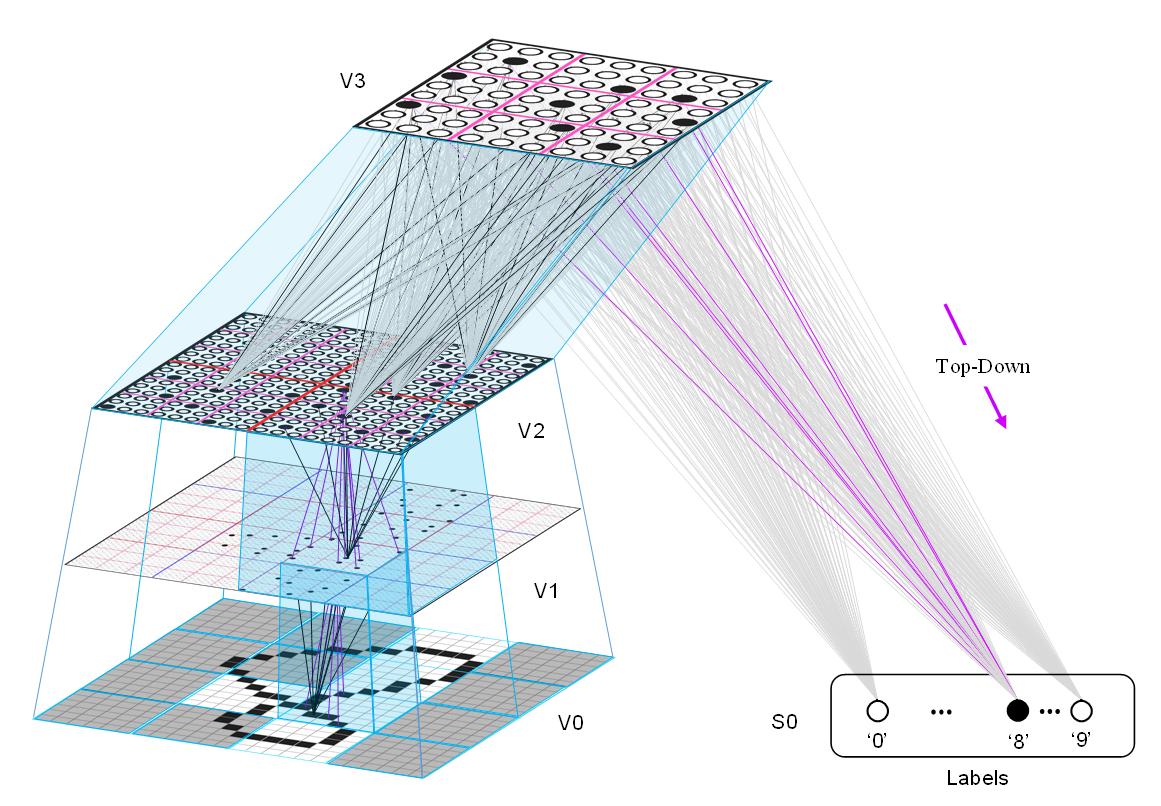
This next figure simply shows that in general, label information may interact with pure sensory representations at various levels, possibly in parallel. Of course, humans do not typically receive any sort of supervisory signal (label) at the low visual scales, e.g., V1, maybe V2, etc.